Are your BigQuery costs starting to creep up now that you’ve had Google Analytics 4 connected for a while? Do you have scheduled queries that overwrite the destination table on every run? This post will look at a relatively easy way to run scheduled queries on GA4 data without having to query all the way back to day 1.
Google updates GA4 data for a few days after it is initially gathered, so a lot of the methods that we might ordinarily use to add only new data to a BigQuery table won’t work. Much of the introductory material available correctly guides us to just overwrite the entire output table when scheduling queries.
This is the easiest way to get accurate data, and back when we’d just connected GA4 to BigQuery, the costs of doing it for even pretty busy websites were negligible. But as time goes on, and more data is gathered, the inefficiency of querying old data that hasn’t changed has increasing costs. Here’s a better way that isn’t too complicated
What You’ll Need
We’re assuming that you have scheduled queries you run against the whole date range of your GA4 BigQuery export, and that these queries overwrite the results table when they run.
If you need help with getting your reporting up and running through BigQuery, consider this course on how to Prep GA4 Data in BigQuery for Reporting. Note that it doesn’t just cover the basics – later sections of the course will take you through more sophisticated stuff than we do in this post, but they build up to it.
The Plan: Delete and Insert the Last 7 Days of Data, Every Day
Note that there are lots of ways to do this, and some are more robust and sophisticated, but we are going to take the easy route wherever possible. Instead of trying to append new rows, update changed rows, and delete removed rows, we’re just going to delete the last seven days of data from our destination table, then query the last seven days from the export into our destination table.
This might seem heavy handed, but if you are coming from overwriting the entire date range, it’s a much lighter approach.
We’re also going to add a bit of a safety valve. Sometimes Google Analytics bugs out and data has to be backfilled, so we will still overwrite the whole table occasionally. It will also clear up some minor inconsistencies that might arise in your data. This clever idea came from June Li at ClickInsight. We’ve got things set up to do this quarterly in the example below, but you’ll see how you can modify that.
Copy Your Current Tables
We’re going to start by creating test versions of the tables you want to update. The easiest way I found to do this was to take the query I currently use to generate the table, wrap it in parentheses, and stick a CREATE command in front of it.
CREATE TABLE
destination_dataset.destination_table_name
PARTITION BY
Date
AS (
SELECT
cast(event_date as DATE format 'YYYYMMDD') as Date,
-- ...
FROM `your_project.analytics_XXXXXXXXX.events_*`
WHERE
_table_suffix between
-- your first day of data as a YYYYMMDD string, eg 20240101
'your_first_day_of_data_as_YYYYMMDD' and
format_date('%Y%m%d',date_sub(current_date(), interval 1 day))
)
Give your tables a clear name, but note that if you keep them in the same dataset as your production tables, you can just rename them when you are done testing and ready to switch over.
Next, instead of configuring partitioning as part of the scheduled query UI , we are going to define our partitioning in the query itself.
Then comes AS ( the original query ). Obviously, the query needs to include the partition column (which you can name however you please, but ours is just called Date).
Beyond that, you can go to town!
Wait, Should I Test This First?
I highly recommend testing the new versions of your queries against the old ones, because, well, you should always check data for accuracy when you change how it’s processed. In my testing I did detect some minor inconsistencies in one of my queries. In a query to generate a pageview table with session level attribution, I noticed a very small number of pageviews got attributed differently.
I’m guessing these were part of sessions that spanned midnight of the cutoff point seven days ago, and the original attribution data from the beginning of the session was lost. In the case of this query and the data it was running against, the difference was negligible, but that might not always be the case. And, we will run the full overwrite of the tables quarterly, which will keep these inconsistencies from accumulating.
What’s the Easiest Way to Test This?
Here’s the testing plan I used:
- Create copies of scheduled query result tables (done above)
- Check table row counts to make sure they are identical across test copies and production originals
- Create scheduled queries to run on the last seven days for a day or two, do a full refresh, then run on the last seven days for another day or two (we go into this in detail later).
- You can check your results at any point in the process, but waiting through a couple normal seven day pulls, then a full overwrite, and another couple seven day pulls, reproduces both date ranges for the query, in their natural sequence.
- Check tables for row level discrepancies using the query shared here by Mark Scannell https://medium.com/google-cloud/bigquery-table-comparison-cea802a3c64d
You can also connect the tables to copies of reports you currently run from your full overwrite tables and compare the final output. This is particularly useful if you turned up row level discrepancies whose impact you need to investigate.
Prepare a DELETE and INSERT Query
Much like we just added some stuff to the beginning of the query we used to overwrite tables to make it create a new table with the same data, we will add commands to the beginning of our old queries in this step. Note that, unlike before, we don’t need to wrap our original query in parentheses. I start with images as they are easier to decipher, what with the colours and indents, but the code is available at the end of this section in copy and paste/screen reader friendly text.
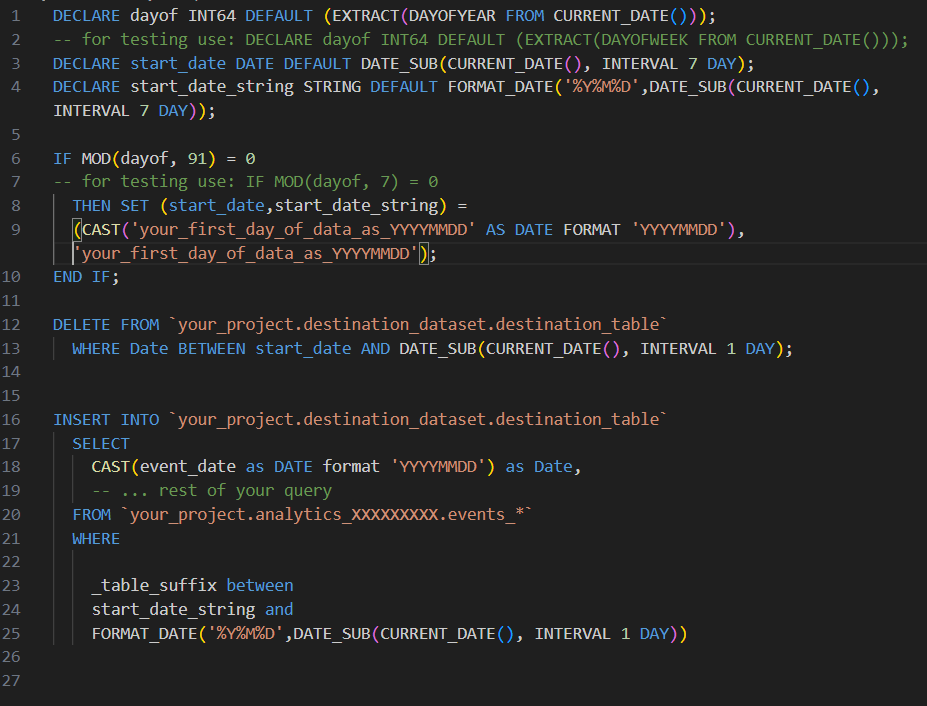
Let’s break this into parts:
We start by declaring and setting some useful default values in variables

- dayof: this is an integer that tells us how many days into the current year we are. The testing version gives the day of the week instead.
- start_date: the date we want to start pulling data from, which defaults to seven days ago.
- start_date_string: same as start_date but in a string data type so we can easily pass it as a table suffix later.
Next, we decide if we are going to do a full overwrite or stick to a seven day overwrite

We use the MOD function with the dayof variable and the number of days we want to go between full overwrites. If the day of the year divided by 91 has no remainder (so, every quarter), we do a full overwrite. You can adjust the number you divide by to set the frequency with which you want to do the full overwrite.
The testing version of the MOD function divides by seven, and the test version of the dayof variable set in the previous step gives the day of the week, starting from Sunday. So in test mode, you’d get your full refresh every Saturday. Perfect for setting this up one week and testing the next, but again, you can adjust the numbers to your liking.
If our modulus is 0, we change the values of start_date and start_date_string to represent the first day of data we gathered. Otherwise, we leave them at at 7 day lookback window we set above.
DELETE the Old

Note that the WHERE clause is using the Date column we set as our partition. Again, you can call this column whatever you’d like, but deleting (and inserting) based on the partition column uses far less data than otherwise.
INSERT the New
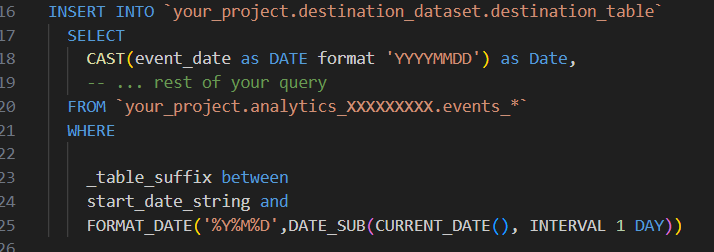
Finally, we insert the data from the query we’ve always used into the destination table. The big difference is, instead of always going all the way back to our first day of data, we set the beginning _table_suffix to start_date_string. And most of the time, that start_date_string will only be going back a week – think of the query data you’ll save!
Schedule the DELETE and INSERT Query
There are a couple important differences in how we schedule this kind of query where we specify destinations directly in the query. As you might have guessed, you DO NOT tick the Set a destination table for query results box, as we’ve established the destination in the query and the overwrite vs append behavior in the query itself.
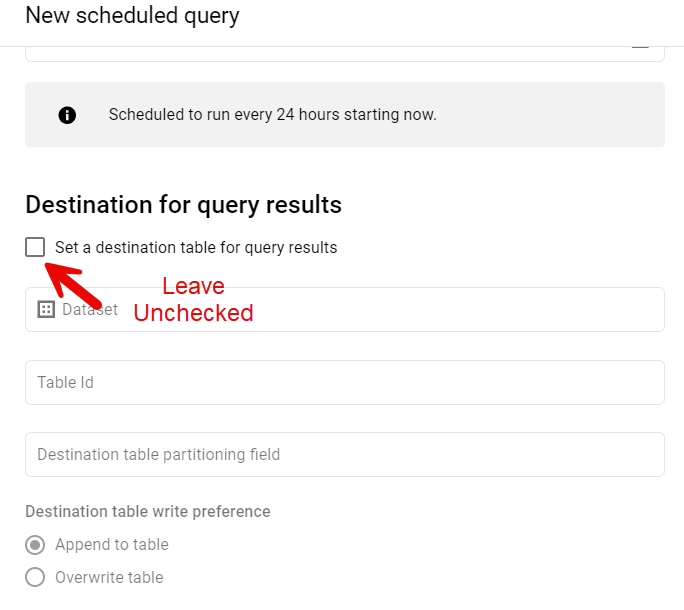
Otherwise this is no different from scheduling a normal query.
I hope you found this helpful and that you’re looking forward to saving a bunch of data. If you have any questions or other feedback, please leave a comment or contact me!
Here’s the plain text version:
DECLARE dayof INT64 DEFAULT (EXTRACT(DAYOFYEAR FROM CURRENT_DATE()));
-- for testing use: DECLARE dayof INT64 DEFAULT (EXTRACT(DAYOFWEEK FROM CURRENT_DATE()));
DECLARE start_date DATE DEFAULT DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY);
DECLARE start_date_string STRING DEFAULT FORMAT_DATE('%Y%M%D',DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY));
IF MOD(dayof, 91) = 0
-- for testing use: IF MOD(dayof, 7) = 0
THEN SET (start_date,start_date_string) =
(CAST('your_first_day_of_data_as_YYYYMMDD' AS DATE FORMAT 'YYYYMMDD'),'your_first_day_of_data_as_YYYYMMDD');
END IF;
DELETE FROM `your_project.destination_dataset.destination_table`
WHERE Date BETWEEN start_date AND DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY);
INSERT INTO `your_project.destination_dataset.destination_table`
SELECT
CAST(event_date as DATE format 'YYYYMMDD') as Date,
-- ... rest of your query
FROM `your_project.analytics_XXXXXXXXX.events_*`
WHERE
_table_suffix between
start_date_string and
FORMAT_DATE('%Y%M%D',DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))
Thank you for your article. The most cost-effective way to add new tables incrementally is by using dataform and running it incrementally to identify the exact table_id created each day. This approach allows us to query only one table instead of 7 days’ worth of data.
Thanks for the comment, Ali! This post isn’t looking for the cheapest or most robust way to manage the process of getting GA4 data through BigQuery and into reports, so much as the one most accessible to analysts less familiar with the Google Cloud Platform. This method is presented as an improvement over using scheduled queries that overwrite entire tables, without having to learn Dataform.
Dataform is indeed a more powerful option, but it is also a more complicated one, that I feel it makes sense to build up to. As a result, I’m planning on doing some posts on using Dataform come July.